As a full stack engineer, you will be dealing a lot with the ubiquitous HTTP protocol. In this article I will cover various aspects of HTTP that you should know about. By the end of this article, you should have a good understanding of HTTP. This article will server as a reference for you to come back to when you need to brush up on HTTP. I hope you find this article useful and learn something new about HTTP.
If I missed anything, please let me know in the comments below. Happy reading!
What is a URL
URLs are addresses that are used to access resources on the internet and an important part of using HTTP. They are made up of a protocol, domain, path, query, fragment, port, username, password, and TLD.
These are the components of a URL:
| Name | Description | Example |
|---|---|---|
| Protocol | The protocol that will be used to access the resource. Most browsers now defaults to https unless explicitly stated otherwise | https |
| Domain | The domain that the resource is accessed from. | example.com |
| Path | The path where the resource resides | /path/to/resource |
| Query | Queries are extra information sent to the server to customize the request | ?query=string |
| Fragment | Fragments are used by browsers/clients to track progress in the document. It is never sent to the server as part of a request | #fragment |
| Port | The port where the server is running. It defaults to 80 for http and 443 for https | :8080 |
| Username | The username indicates to the server the identity of that who is accessing the resource. It defaults to annoymous | username |
| Password | Some resources are protected and the server can demand credentials. It defaults to empty | password |
| TLD | The top-level domain is used by clients to know where to find the domain name in the URL | com |
Here is an example of a URL:
https://username:password@example.com/path/to/resource?query=string#fragment
HTTP Methods
HTTP requests are made up of a method, path, headers, and body. The method is
the most important part of the request because it tells the server what to do
with the request. There are 6 methods that are commonly used: GET, POST,
PUT, DELETE, HEAD, and OPTIONS. There is a seventh method called TRACE
that is rarely used. but will be covered here for completeness.
A typical HTTP request looks like this:
GET /path/to/resource HTTP/1.1
Host: example.com
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:89.0) Gecko/20100101 Firefox/89.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate, br
Connection: keep-alive
Request Headers will be discussed in more detail later in this article.
Safe Methods
The GET and HEAD HTTP methods are idempotent, which means that they can be
called multiple times without changing the state of the server. They are often
referred to as safe methods because they do not change the state of the server.
Unsafe Methods
The POST, PUT, DELETE, and OPTIONS HTTP methods are not idempotent. they
can potentially change the state of the server.
GET
This is the most commonly used method of the HTTP. It is the method used by browsers when you type in a URL in the address bar. It instructs the server to send the resource to the client.
GET /items/snickers HTTP/1.1
Host: www.foo-bar.com
Accept: *
POST
POST were meant to be used for sending input data to the server but in practice are commonly used by HTML forms. If following a strict interpretation of the HTTP specification, POST should be used for sending input data to the server.
If you are designing a REST API, you should use POST for creating a new resource.
POST /items HTTP/1.1
Host: www.foo-bar.com
Accept: *
Content-Type: application/json
{
"name": "snickers",
"price": 1.99
}
PUT
PUT is used to update an existing resource on the server. If the resource does not exist, it will be created. If you are designing a REST API, you should use PUT for updating an existing resource.
PUT /items/snickers HTTP/1.1
Host: www.foo-bar.com
Accept: *
Content-Type: application/json
{
"name": "snickers",
"price": 3.00
}
DELETE
DELETE is used to delete an existing resource on the server. If you are
designing a REST API, you should use DELETE for deleting an existing resource.
DELETE /items/snickers HTTP/1.1
Host: www.foo-bar.com
Accept: *
HEAD
The HEAD method can be referred to as lite GET. It behaves like a GET
request but does not return the body of the response. It is used to get the
headers of a resource on the server.
This is useful for checking if a resource exists without having to download the
entire resource. Using HEAD can save bandwidth and time. Here are some use
cases for HEAD:
- Checking if a resource exists by inspecting the status code of the response.
- Checking if a resource has been modified e.g by inspecting the last modified headers.
- Inspect the type of a resouce by inspecting the content type headers.
HEAD /items/snickers HTTP/1.1
Host: www.foo-bar.com
Accept: *
OPTIONS
The OPTIONS method is used to query an HTTP server about what methods are
allowed on a resource. The most common use case of this method is when browsers
use this method when making a CORS request to check if the server allows the
request.
When a web page attempts to make a CORS request, the browser will first make
an OPTIONS request to the server to check if the server allows the request. If
the server allows the request, the browser will then make the actual request. If
the server does not allow the request, the browser will not make the actual
request.
HTTP Request
OPTIONS /items/snickers HTTP/1.1
Host: www.foo-bar.com
Access-Control-Request-Method: DELETE
HTTP Response
HTTP/1.1 200 OK
Access-Control-Allow-Methods: GET, POST, PUT, DELETE, HEAD, OPTIONS
TRACE
The TRACE method is used to check if a request has been modified by a proxy
server. It is rarely used in practice. It is good for debugging purposes. Lets
look at an example of a request going through the internet. The figure below
what most be happening when you make a request to a server.
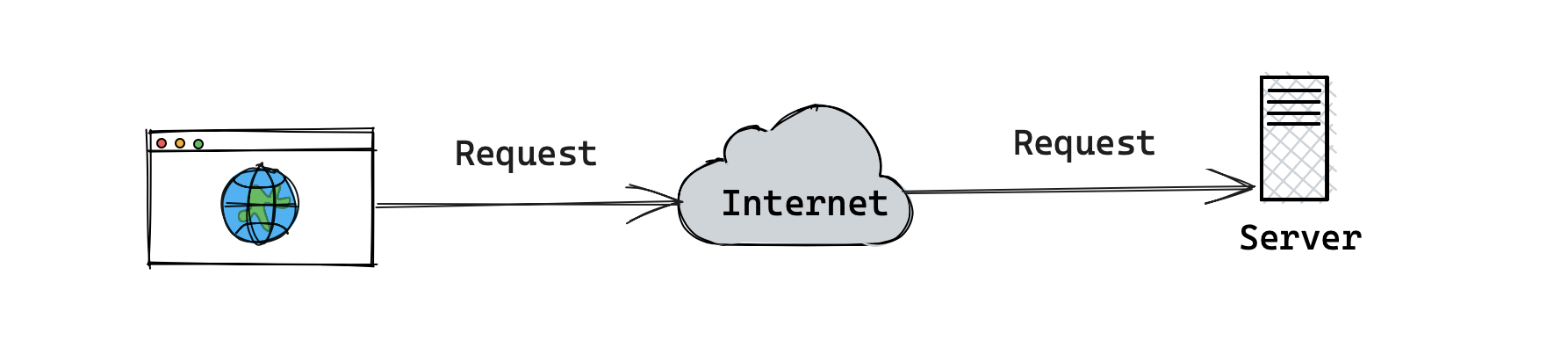
but in reality, the requests usually go through multiple proxies before reaching their destination and each proxy can potentially modify the request. The figure below shows what happens when a request goes through a proxy.
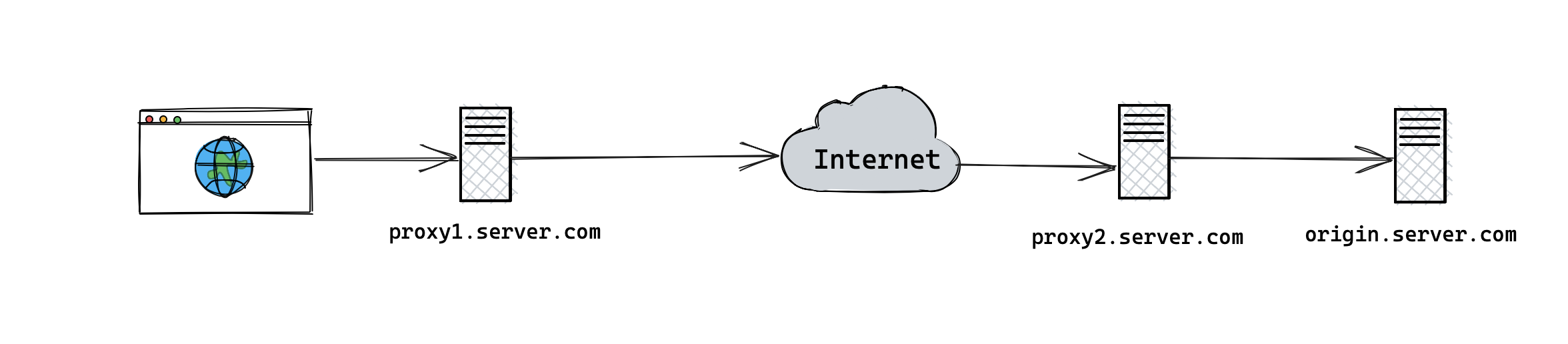
This is where the TRACE method comes in handy. When web servers receive a
TRACE request, they effectively just echo the request back to the client.
TRACE /items/snickers HTTP/1.1
Host: www.foo-bar.com
Accept: *
HTTP/1.1 200 OK
Content-type: text/plain
Content-length: 96
Via: 1.1 proxy1.server.com
TRACE /items/snickers HTTP/2
Host: www.foo-bar.com
Accept: *
Via: 1.1 proxy2.server.com
You can see that the request has been modified by the proxy server by upgrading
the HTTP version from HTTP/1.1 to HTTP/2 and adding a Via header. This is
useful for debugging purposes.
HTTP 2
HTTP 2 is the latest version of the HTTP protocol. It is faster than HTTP 1.1 because it uses binary encoding instead of text encoding. It also supports multiplexing, which means that multiple requests can be sent over a single connection. It also supports server push, which means that the server can send resources to the client before the client requests them.
- HTTP 2 is a binary protocol. This means that it uses binary encoding instead of text encoding. This makes it faster than HTTP 1.1.
- HTTP 2 also supports multiplexing, which means that multiple requests can be sent over a single connection. This is super useful for reducing latency.
- HTTP 2 also supports server push, which means that the server can send resources to the client before the client requests them.
Multiplexing
To understand multiplexing, we need to understand how HTTP 1.1 works. HTTP 1.1
is a sequential protocol, it sends a request one at a time. This means that if
you have a web page with multiple resources hosted on the same host, the browser
will have to make multiple requests to the server to get all the resources. This
can be slow because each request has to wait for the previous request to finish
before it can be sent. This limitation applies to make other requests like
CORS.

HTTP 2 uses a single connection to send multiple requests to the same host if the server supports http 2. This means that if you have a web page with multiple resources, the browser will have to make a single request to the server to get all the resources. This is much faster because the browser does not have to wait for the previous request to finish before it can send the next request.

HTTP Response Codes
The list of HTTP Response codes is long, but I wil list the most important ones here. The most important ones are the 200 series, which means that the request was successful. The 300 series means that the request was redirected. The 400 series means that the request was invalid. The 500 series means that the server encountered an error.
- 2xx - Success
| Code | Code Text | Explanation |
|---|---|---|
| 200 | OK | The request was successfully executed by the server, common with GET requests |
| 201 | Created | When a resource was successfully created, might not return a response body |
| 202 | No Content | The request was successful but no content is returned |
| 206 | Partial Content | This is common with streaming applications. A client can request a partial content using the `range: bytes=100" header |
| Code | Code Text | Explanation |
|---|---|---|
| 301 | Moved Permanently | The resource has been moved permanently to a new location |
| 302 | Found | The resource has been moved temporarily to a new location. |
| Code | Code Text | Explanation |
|---|---|---|
| 400 | Bad Request | The request was invalid. Usually a wrong parameter somewhere in the request payload |
| 401 | Unauthorized | Authentication is required to access this resource. This usually means a missing Authorization Header |
| 403 | Forbidden | Forbidden, This is probably due to a lack of an authenticated token |
| 403 | Not Found | The requested resource was not found on this server |
| Code | Code Text | Explanation |
|---|---|---|
| 500 | Internal Server | The server probably threw an exception when processing the request |
| 502 | Bad Gateway | |
| 503 | Service Unavailable | This might be due to a reverse proxy server or CDN unable to reach the origin HOST in the request header |
| 504 | Gateway Timeout | The request timed out |
Cross-Origin Resource Sharing (CORS)
Cross-Origin Resource Sharing (CORS) is a mechanism that allows HTTP requests to be made on a web page to servers that are not in the same domain as the web page where the request originates from.
Browser security policies prevents such requests begin made by default,
therefore, when a request is made by Javascript from a web page, the browser
will make a Preflight check to the server to check if the server allows the
request. If the server allows the request, the browser will make the actual
request. If the server does not allow the request, the browser will not make the
actual request.
If you are developing a server that is meant to support CORS requests, i.e a server that is meant to be accessed by a web page, you need to configure the server to allow CORS requests. e.g
Bun.serve({
// Request Handler
async fetch(request: Request): Promise<Response> {
if(request.method.toLowerCase() === 'options') {
return new Response('ok', {
headers: {
// Set the host that is allowed to make requests to this server or use '*' to allow all hosts
'Access-Control-Allow-Origin': '*',
// Set the methods that are allowed to be used to make requests to this server
'Access-Control-Allow-Methods': 'GET, POST, PUT, DELETE, HEAD, OPTIONS',
// Set the headers that are allowed to be used to make requests to this server
'Access-Control-Allow-Headers': 'Content-Type, Authorization',
// Set the amount of time that the browser should cache the response
'Access-Control-Max-Age': '86400',
// Set whether or not the browser should send credentials with the request
'Access-Control-Allow-Credentials': 'true',
// Set the headers that are allowed to be exposed to the client
'Access-Control-Expose-Headers': 'Content-Type, Authorization'
}
})
} else {
// Handle the requests here
return new Response('ok')
}
}
})
The image below shows what happens when a web page attempts to make a CORS to
the bar.com domain to fetch a list of items. The browser will first make a
Preflight OPTIONS request to check with bar.com if this request is permitted.
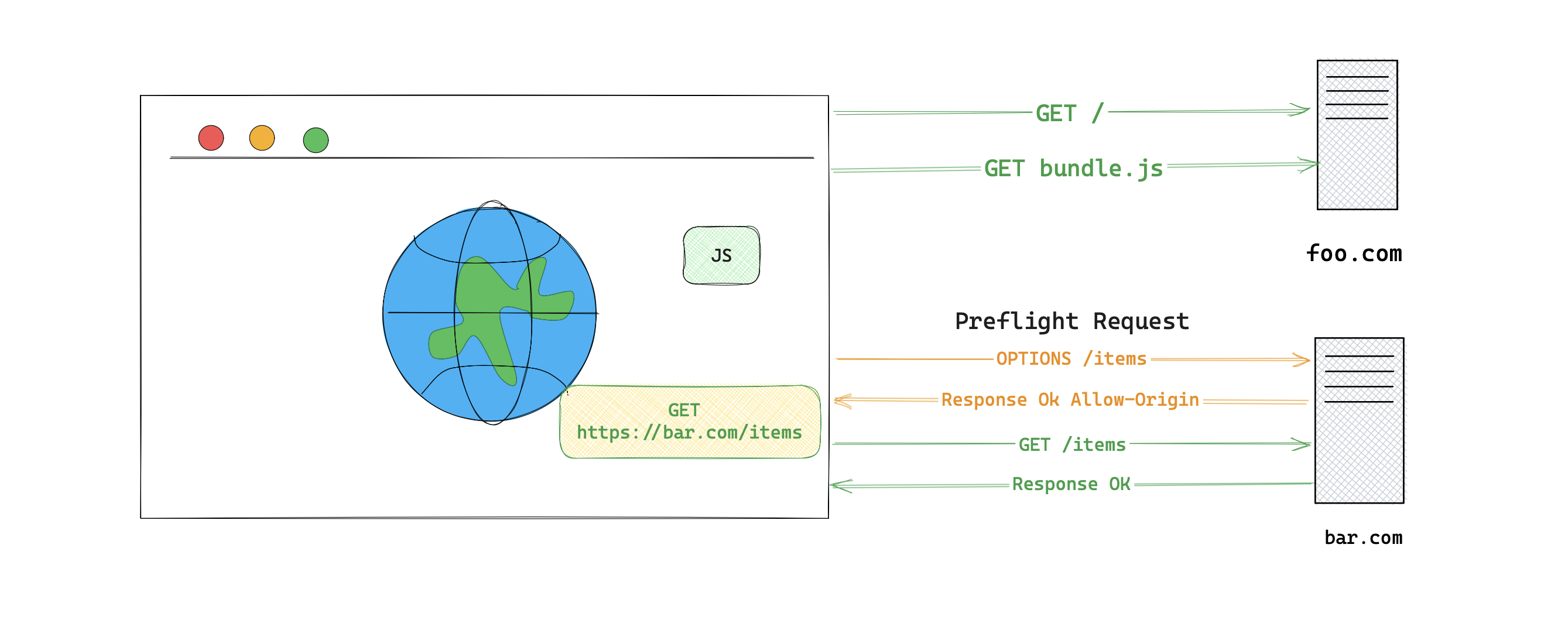
Authentication
The HTTP protocol supports two types of authentication: Basic Authentication
and Digest Authentication. There are other forms of authentication like
Token Authentication, OAuth, and JWT that are not part of the HTTP
protocol but are commonly used in web applications. These forms of authentication goes beyond the scope of this article.
Basic Authentication
HTTP Basic Authentication perhaps the least secure form of authentication on the
web but it is the simplest to implement. It works by sending the username and
password in the Authorization header of the request. The username and password
are encoded using base64 encoding. This is not secure because base64 encoding is
not encryption. It is just a way to encode data in a format that can be easily
decoded. This means that anyone can decode the username and password and use it
to access the resource.
The image below shows how basic authentication works.

The browser makes a request to the server at bar.com.
The server responds with a
401 Unauthorizedresponse.The browser challenges the user for the username and password.
The browser then Base64 encodes the credentials as
Base64(username:password)and includes in the next requestAuthorizationheader.If the username and passwords are correct then server responds with a
200 OKresponse.Here is a simple implementation of this in Bun:
// Start a simple server that challenges the user for a username and password
Bun.serve({
port: 3000,
fetch(request: Request) {
const authorization = request.headers.get('Authorization') ?? ''
const decodedAuth = atob(authorization.replace('Basic ', ''))
const [username, password] = decodedAuth.split(':')
// Extract the super secure authentication
// These credentials could be stored in a database or a file paired with the realm
if (username === 'admin' && password === 'admin') {
return new Response('Hello, admin!, Here is your document')
} else {
// The realm is used to tell the user what resource they are trying to access
// Different credentials can be required for different realms (Resources)
return new Response('Unauthorized', { status: 401, statusText: 'Authorization Required', headers: {
'WWW-Authenticate': 'Basic realm="docs", charset="UTF-8"'
} })
}
}
})
This should go without saying that this is a very very very bad way of securing
a resource over the internet but it was what was available in the early days of
HTTP. The username and password in this case are sent in clear text.
Digest Authentication
Digest Authentication is a slight better way of doing authentication over the web. It follows the same steps as Basic Authentication but instead of sending the username and password in clear text, it sends a hash of the username, password, and other information. This is more secure than Basic Authentication because the username and password are not sent in clear text. The image below shows how Digest Authentication works.
In this case, the server will over a nounce and a hashing algorithm for the
browser to use to encrypt the credentials. The server will then recalculate the
hash and compare it with the hash sent by the browser. If the hashes match, the
server will respond with a 200 OK response.

Caching
The internet thrives on caching. Caching is a way to temporarily store resources as close to the client as possible. If you are working on a high traffic website, caching is a must. It is a way to reduce the load on your servers and make your website faster. Caching is usually done at a CDN level as they are mostly closer to end users than your servers. Caching can also be done at the server level. This is useful for caching resources that are not static e.g a user’s profile page.
The following diagram shows a simplistic view of how caching works:


The main task of a developer is to determine how a cache resource can be revalidated by using one the HTTP caching headers Cache-Control, Expires, ETag, and Last-Modified headers.
CDNs will make use of HTTP conditional requests to determine if a resource is stale or not. This is done by using the If-Modified-Since, If-None-Match, and If-Range headers.
Cache-Control
The Cache-Control header is used to tell the browser/CDN how long to cache a
resource. It is used by the browser/CDN to determine if it should make a request
to the server or use the cached version of the resource. It is the easiest way
to control caching.
Once the time runs out, the browser/CDN will make a request to the origin server to refresh its cache with a new version of the resource.
The Cache-Control header has the following directives:
| Directive | Description |
|---|---|
public | The resource can be cached by the browser and shared with other |
private | The resource can be cached by the browser but cannot be shared |
no-cache | The resource must not be cached by the browser/CDN. |
no-store | The resource be cached by the browser/CDN but must be validated with the origin server before being served . |
max-age | The amount of time that the browser should cache the resource. |
Here is a simple implementation of this in Bun:
Bun.serve({
port: 3000,
fetch(request: Request) {
return new Response('Hello, World!', {
headers: {
'Cache-Control': 'public, max-age=86400'
}
})
}
})
The above code will tell the browser to cache the response for 1 day. The response will look like this:
HTTP/1.1 200 OK
Date: Sat, 29 Jun 2023, 14:30:00 GMT
Content-type: text/plain
Cache-Control: public, max-age=86400
Cache-Control Revalidation
The browser/CDN will make a request to the origin server to check if the resource has been modified. This is done by using the If-Modified-Since header. If the resource has not been modified, the origin server will respond with a 304 Not Modified response. If the resource has been modified, the origin server will respond with a 200 OK response.
CDN Request will look like this:
GET /items/snickers HTTP/1.1
Host: www.foo-bar.com
Accept: *
If-Modified-Since: Sat, 29 Jun 2023, 14:30:00 GMT
The origin server’s response will look like this if the resource has not been modified:
HTTP/1.1 304 Not Modified
Expires
The Expires header is an older way to control caching. It basically does the same thing as the Cache-Control header expect it specifies a date in the future instead of a cache duration.
A typical response with the Expires header looks like this:
HTTP/1.1 200 OK
Date: Sat, 29 Jun 2023, 14:30:00 GMT
Content-type: text/plain
Expires: Fri, 05 Jul 2025, 05:00:00 GMT
ETag
A more advanced way to control caching is to use the ETag header. The ETag header is used to tell the browser/CDN if a resource has been modified. It is used by the browser/CDN to determine if it should make a request to the origin server
or use the cached version of the resource.
The ETag header is usually hash of the resource that is being served by the origin server. If the resource has been modified,
the hash will be different. If the resource has not been modified, the hash will
be the same.
ETag Revalidation
The browser/CDN will make a request to the origin server to check if the resource has been modified. This is done by using the If-None-Match header. If the resource has not been modified, the origin server will respond with a 304 Not Modified response. If the resource has been modified, the origin server will respond with a 200 OK response.
CDN Request will look like this:
GET /items/snickers HTTP/1.1
Host: www.foo-bar.com
Accept: *
If-None-Match: "1234567890"
The origin server’s response will look like this if the resource has not been modified:
HTTP/1.1 304 Not Modified
ETag: "1234567890"
HTTP Cookies
Cookies are a way for the server to tell the client that it is allowed to access a resource. This is useful for restricting access to resources that are only available to certain users.
How Cookies Work
Cookies work by storing data on the client’s computer. The server then sends the cookie to the client. The client then sends the cookie back to the server on subsequent requests.
Cookie Attributes
Domain- The domain that the cookie is valid for.Path- The path that the cookie is valid for.Expires- The date that the cookie expires.Max-Age- The amount of time that the cookie is valid for.Secure- Whether or not the cookie is only sent over HTTPS.HttpOnly- Whether or not the cookie is only sent over HTTP.SameSite- Whether or not the cookie is only sent to the same site.
Cookie Security
Cookies are not secure by default. They can be stolen by a malicious user. To
make cookies secure, they must be encrypted. This is done by using the Secure
attribute.
Internationalization
The HTTP protocol supports internationalization. This means that the protocol is able to support different languages. This is done by using the Accept-Language header. The Accept-Language header is used to tell the server what language the client prefers. The server can then respond with a resource in the language that the client prefers.
The Accept-Language header has the following format:
Accept-Language: <language> [;q=<weight>]
HTTPS
HTTPS is a way for the server to tell the client that it is allowed to access a resource. This is useful for restricting access to resources that are only available to certain users.
How HTTPS Works
HTTPS works by encrypting the data that is sent between the client and the
server. This is done by using the TLS protocol. For example, the following
code is vulnerable to HTTPS:
Bonus
Here are some other things that you should know about HTTP but not strictly about the protocol